- About MAA
- Membership
- MAA Publications
- Periodicals
- Blogs
- MAA Book Series
- MAA Press (an imprint of the AMS)
- MAA Notes
- MAA Reviews
- Mathematical Communication
- Information for Libraries
- Author Resources
- Advertise with MAA
- Meetings
- Competitions
- Programs
- Communities
- MAA Sections
- SIGMAA
- MAA Connect
- Students
- MAA Awards
- Awards Booklets
- Writing Awards
- Teaching Awards
- Service Awards
- Research Awards
- Lecture Awards
- Putnam Competition Individual and Team Winners
- D. E. Shaw Group AMC 8 Awards & Certificates
- Maryam Mirzakhani AMC 10 A Awards & Certificates
- Two Sigma AMC 10 B Awards & Certificates
- Jane Street AMC 12 A Awards & Certificates
- Akamai AMC 12 B Awards & Certificates
- High School Teachers
- News
You are here
Patterns in Pascal's Triangle - with a Twist - One-Dimensional Cellular Automata
There has been considerable interest recently in structures called cellular automata. The most famous example of a cellular automaton is probably John Conway's Game of Life. Cellular automata have been used to model a number of natural phenomena, including the spread of fires and disease. PascGalois Triangles are examples one-dimensional cellular automata. We can also look at two-dimensional cellular automata with similar constructions and at one-dimensional cellular automata with slightly different constructions.
A one-dimensional cellular automaton is a row of cells, each of which has some value from a finite alphabet, together with a local rule for changing the values of the cells in discrete time steps. A configuration in which each cell has a specific value from the alphabet is called a state. The local rule, called the update rule, assigns a new value to a cell based on its current value and the values of its neighbor cells.
For example, Pascal's Triangles mod n or the PascGalois Triangles discussed in section 3 can be viewed as one-dimensional cellular automata with an infinite number of cells. First, consider each row of the triangle as extending indefinitely in either direction, with the "hidden" cells outside the triangle assigned values of zero or the group identity. Each entry of the triangle corresponds to a cell and its value. We update the automaton by combining the current value of a cell with the current value of the cell directly to the right of it and then place the row of cells with new values directly below the old row. This gives the PascGalois triangle skewed to the right. For example, here are two versions of the first 125 rows of Pascal's Triangle mod 5 (or the PascGalois triangle for Z5):
 |
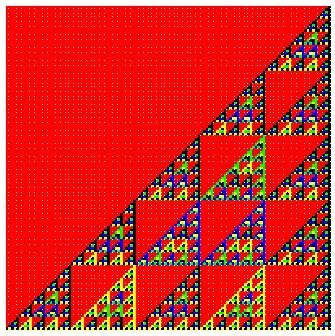 |
This is an example of an infinite cellular automaton. Remember that each row of these pictures represents a different state of the automaton, so that as you move down the rows, you are moving through the temporal evolution of the automaton. Of course, for this to generalize to PascGalois triangles with two different values down the two sides, we have to begin with a row with two non-identity entries. With Pascal's Triangle mod n, we can begin with the top row with a single entry of one.
 We can also define related finite cellular automata either by fixing the values of the cells on the ends or by wrapping the cellular automata around so that the cell on the right of the last cell is defined to be the first cell, and the cell on the left of the first cell is defined to be the last cell. Essentially, you define your automaton as if the row of cells is in fact a circle of cells. You can then apply the same update rule. Suppose we do the mod 5 example again with 25 cells wrapped into a circle -- see the figure at the right.
We can also define related finite cellular automata either by fixing the values of the cells on the ends or by wrapping the cellular automata around so that the cell on the right of the last cell is defined to be the first cell, and the cell on the left of the first cell is defined to be the last cell. Essentially, you define your automaton as if the row of cells is in fact a circle of cells. You can then apply the same update rule. Suppose we do the mod 5 example again with 25 cells wrapped into a circle -- see the figure at the right.
Notice that the values begin to repeat, i.e. the last 25 rows look just like the first 25. In fact, this particular cellular automaton repeats every 100 rows. Since we have only finitely many cells and only finitely many values they can take on, the cellular automaton has finitely many possible states, so eventually it has to repeat a state it has already taken on. Once it does that, the subsequent states will also repeat. With finite cellular automata, no matter what state you begin with, you always evolve to a repeating cycle eventually. This repeating cycle is called a periodic cycle. The states taken on before reaching the periodic cycle are called transient states. For our example, since the entire set of states repeats, there are no transient states.
If we try this with 18 cells instead of 25, the periodic cycle contains 2232 states, and the initial state, the one with only one nonzero value, does not repeat -- it is transient.
- What makes this case different?
- Can we predict in advance what the length of the periodic cycle will be?
- Does the length of the periodic cycle change if we begin with a different initial state, or does it depend only on the number of cells we're using?
- If we use some group multiplication other than Z5, how will that change things?
It is relatively easy to play around with examples and to make conjectures about them, but proving the conjectures is another matter.
In addition to looking at other groups, we can look at other update rules. For example, you might define the new value of a cell to be the sum (or the product, using group multiplication) of the value of the cell to the left and the value of the cell to the right. Our undergraduate research students have been able to answer some of the questions that arise in these investigations -- see Gymnich (2002) and Miller (2001) for some examples -- but there are still many questions left to explore
Kathleen M. Shannon and Michael J. Bardzell, "Patterns in Pascal's Triangle - with a Twist - One-Dimensional Cellular Automata," Convergence (December 2004)



